
What do we do when there are multiple opinions on the best approach to use to tackle a particular problem?
Quite often, we end up going with the HiPPO – the Highest Paid Person’s Opinion, as described in Richard Nisbett’s book Mindware.
But a better way is to use a data-driven approach to testing options and selecting the one that works best.
A/B testing is one of the simplest and oldest methods around.
It’s also called bucket testing or split-run testing, and has been around for a long time.
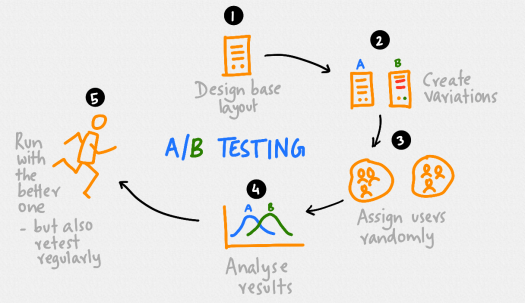
In essence, it has 5 steps we need to go through.
We start by selecting a situation – we may need to solve a new problem or improve an existing situation.
Take, for example, the issue of GDPR compliance.
Many companies are sending out emails to their lists asking them to confirm if they want to stay on the list and what they want to receive.
What should it say? Perhaps we should come up with a base layout.
Maybe we can start with one that explains GDPR in detail and then asks people to update their details. This is the control.
Should we just send out one email?
That’s not something that can be answered easily because we don’t have any data – do we just need to get a decision from someone?
Or can we run a test?
Say we have a database of a thousand people.
We might create variations of the base layout – instead of explaining GDPR we write one that simply says this email is being sent to comply with the GDPR, perhaps linking to a site that explains what it is, and stresses the benefits of staying in the list and what they will get for most of the copy.
We wouldn’t run the test on the entire database. Instead, we select a sample, perhaps 100 users picked at random out of the list.
Then, we assign users randomly. Of the 100 users in the test sample, 50 will get the control version of the email, and the rest the variation.
Then we look at the responses and analyse results.
This might require some familiarity with statistics and the ability to interpret what a statistically significant difference is and if the variations has performed better than the control.
If the variation performs better than the control, we run with it and send it to the entire list.
In theory, this should produce a better outcome. By testing and selecting options based on how well they have performed according to the data, we should boost results.
We need to remember to retest on a regular basis. Some of our results may be false positives, so we need to watch out for errors or more general changes in the environment.
It’s important to recognise that the aim of this approach is to select the one that gives the user clearer information and a better experience.
It’s also a defensible approach that takes away much of the arguing and opinions that often accompanies choices that involve strategies or the wording of copy.
Instead, we can just offer to run an A/B test and go with the evidence.

One Reply to “”